Latest posts for tag debian
Debugging printing to a remote printer
I upgraded to Debian testing/trixie, and my network printer stopped appearing in print dialogs. These are notes from the debugging session.
Check firewall configuration
I tried out kde, which installed plasma-firewall, which installed
firewalld, which closed by default the ports used for printing.
For extra fun, appindicators are not working in Gnome
and so firewall-applet is currently useless, although one can run
firewall-config manually, or use the command line that might be more user
friendly than the UI.
Step 1: change the zone for the home wifi to "Home":
firewall-cmd --zone home --list-interfaces
firewall-cmd --zone home --add-interface wlp1s0
Step 2: make sure the home zone can print:
firewall-cmd --zone home --list-services
firewall-cmd --zone home --add-service=ipp
firewall-cmd --zone home --add-service=ipp-client
firewall-cmd --zone home --add-service=mdns
I searched and searched but I could not find out whether ipp is needed,
ipp-client is needed, or both are needed.
Check if avahi can see the printer
Is the printer advertised correctly over mdns?
When it didn't work:
$ avahi-browse -avrt
= wlp1s0 IPv6 Brother HL-2030 series @ server UNIX Printer local
hostname = [server.local]
address = [...ipv6 address...]
port = [0]
txt = []
= wlp1s0 IPv4 Brother HL-2030 series @ server UNIX Printer local
hostname = [server.local]
address = [...ipv4 address...]
port = [0]
txt = []
$ avahi-browse -rt _ipp._tcp
[empty]
When it works:
$ avahi-browse -avrt
= wlp1s0 IPv6 Brother HL-2030 series @ server Secure Internet Printer local
hostname = [server.local]
address = [...ipv6 address...]
port = [631]
txt = ["printer-type=0x1046" "printer-state=3" "Copies=T" "TLS=1.2" "UUID=…" "URF=DM3" "pdl=application/octet-stream,application/pdf,application/postscript,image/jpeg,image/png,image/pwg-raster,image/urf" "product=(HL-2030 series)" "priority=0" "note=" "adminurl=https://server.local.:631/printers/Brother_HL-2030_series" "ty=Brother HL-2030 series, using brlaser v6" "rp=printers/Brother_HL-2030_series" "qtotal=1" "txtvers=1"]
= wlp1s0 IPv6 Brother HL-2030 series @ server UNIX Printer local
hostname = [server.local]
address = [...ipv6 address...]
port = [0]
txt = []
= wlp1s0 IPv4 Brother HL-2030 series @ server Secure Internet Printer local
hostname = [server.local]
address = [...ipv4 address...]
port = [631]
txt = ["printer-type=0x1046" "printer-state=3" "Copies=T" "TLS=1.2" "UUID=…" "URF=DM3" "pdl=application/octet-stream,application/pdf,application/postscript,image/jpeg,image/png,image/pwg-raster,image/urf" "product=(HL-2030 series)" "priority=0" "note=" "adminurl=https://server.local.:631/printers/Brother_HL-2030_series" "ty=Brother HL-2030 series, using brlaser v6" "rp=printers/Brother_HL-2030_series" "qtotal=1" "txtvers=1"]
= wlp1s0 IPv4 Brother HL-2030 series @ server UNIX Printer local
hostname = [server.local]
address = [...ipv4 address...]
port = [0]
txt = []
$ avahi-browse -rt _ipp._tcp
+ wlp1s0 IPv6 Brother HL-2030 series @ server Internet Printer local
+ wlp1s0 IPv4 Brother HL-2030 series @ server Internet Printer local
= wlp1s0 IPv4 Brother HL-2030 series @ server Internet Printer local
hostname = [server.local]
address = [...ipv4 address...]
port = [631]
txt = ["printer-type=0x1046" "printer-state=3" "Copies=T" "TLS=1.2" "UUID=…" "URF=DM3" "pdl=application/octet-stream,application/pdf,application/postscript,image/jpeg,image/png,image/pwg-raster,image/urf" "product=(HL-2030 series)" "priority=0" "note=" "adminurl=https://server.local.:631/printers/Brother_HL-2030_series" "ty=Brother HL-2030 series, using brlaser v6" "rp=printers/Brother_HL-2030_series" "qtotal=1" "txtvers=1"]
= wlp1s0 IPv6 Brother HL-2030 series @ server Internet Printer local
hostname = [server.local]https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=1092109
address = [...ipv6 address...]
port = [631]
txt = ["printer-type=0x1046" "printer-state=3" "Copies=T" "TLS=1.2" "UUID=…" "URF=DM3" "pdl=application/octet-stream,application/pdf,application/postscript,image/jpeg,image/png,image/pwg-raster,image/urf" "product=(HL-2030 series)" "priority=0" "note=" "adminurl=https://server.local.:631/printers/Brother_HL-2030_series" "ty=Brother HL-2030 series, using brlaser v6" "rp=printers/Brother_HL-2030_series" "qtotal=1" "txtvers=1"]
Check if cups can see the printer
From CUPS' Using Network Printers:
$ /usr/sbin/lpinfo --include-schemes dnssd -v
network dnssd://Brother%20HL-2030%20series%20%40%20server._ipp._tcp.local/cups?uuid=…
Debugging session interrupted
At this point, the printer appeared.
It could be that:
lpinfosomehow made it work- after opening
ippservices on the firewall and spending enough minutes researching, eventuallycups-browsedcould see the printer - logging into the remote server to list printers woke it up somehow
- the printer just realised I was level headed, determined and not in a hurry.
In the end, debugging failed successfully, and this log now remains as a reference for possible further issues.
ncdu on files to back up
I use borg and restic to backup files in my system. Sometimes I run a huge
download or clone a large git repo and forget to mark it with CACHEDIR.TAG,
and it gets picked up slowing the backup process and wasting backup space
uselessly.
I would like to occasionally audit the system to have an idea of what is a candidate for backup. ncdu would be great for this, but it doesn't know about backup exclusion filters.
Let's teach it then.
Here's a script that simulates a backup and feeds the results to ncdu:
#!/usr/bin/python3
import argparse
import os
import sys
import time
import stat
import json
import subprocess
import tempfile
from pathlib import Path
from typing import Any
FILTER_ARGS = [
"--one-file-system",
"--exclude-caches",
"--exclude",
"*/.cache",
]
BACKUP_PATHS = [
"/home",
]
class Dir:
"""
Dispatch borg output into a hierarchical directory structure.
borg prints a flat file list, ncdu needs a hierarchical JSON.
"""
def __init__(self, path: Path, name: str):
self.path = path
self.name = name
self.subdirs: dict[str, "Dir"] = {}
self.files: list[str] = []
def print(self, indent: str = "") -> None:
for name, subdir in self.subdirs.items():
print(f"{indent}{name:}/")
subdir.print(indent + " ")
for name in self.files:
print(f"{indent}{name}")
def add(self, parts: tuple[str, ...]) -> None:
if len(parts) == 1:
self.files.append(parts[0])
return
subdir = self.subdirs.get(parts[0])
if subdir is None:
subdir = Dir(self.path / parts[0], parts[0])
self.subdirs[parts[0]] = subdir
subdir.add(parts[1:])
def to_data(self) -> list[Any]:
res: list[Any] = []
st = self.path.stat()
res.append(self.collect_stat(self.name, st))
for name, subdir in self.subdirs.items():
res.append(subdir.to_data())
dir_fd = os.open(self.path, os.O_DIRECTORY)
try:
for name in self.files:
try:
st = os.lstat(name, dir_fd=dir_fd)
except FileNotFoundError:
print(
"Possibly broken encoding:",
self.path,
repr(name),
file=sys.stderr,
)
continue
if stat.S_ISDIR(st.st_mode):
continue
res.append(self.collect_stat(name, st))
finally:
os.close(dir_fd)
return res
def collect_stat(self, fname: str, st) -> dict[str, Any]:
res = {
"name": fname,
"ino": st.st_ino,
"asize": st.st_size,
"dsize": st.st_blocks * 512,
}
if stat.S_ISDIR(st.st_mode):
res["dev"] = st.st_dev
return res
class Scanner:
def __init__(self) -> None:
self.root = Dir(Path("/"), "/")
self.data = None
def scan(self) -> None:
with tempfile.TemporaryDirectory() as tmpdir_name:
mock_backup_dir = Path(tmpdir_name) / "backup"
subprocess.run(
["borg", "init", mock_backup_dir.as_posix(), "--encryption", "none"],
cwd=Path.home(),
check=True,
)
proc = subprocess.Popen(
[
"borg",
"create",
"--list",
"--dry-run",
]
+ FILTER_ARGS
+ [
f"{mock_backup_dir}::test",
]
+ BACKUP_PATHS,
cwd=Path.home(),
stderr=subprocess.PIPE,
)
assert proc.stderr is not None
for line in proc.stderr:
match line[0:2]:
case b"- ":
path = Path(line[2:].strip().decode())
case b"x ":
continue
case _:
raise RuntimeError(f"Unparsable borg output: {line!r}")
if path.parts[0] != "/":
raise RuntimeError(f"Unsupported path: {path.parts!r}")
self.root.add(path.parts[1:])
def to_json(self) -> list[Any]:
return [
1,
0,
{
"progname": "backup-ncdu",
"progver": "0.1",
"timestamp": int(time.time()),
},
self.root.to_data(),
]
def export(self):
return json.dumps(self.to_json()).encode()
def main():
parser = argparse.ArgumentParser(
description="Run ncdu to estimate sizes of files to backup."
)
parser.parse_args()
scanner = Scanner()
scanner.scan()
# scanner.root.print()
res = subprocess.run(["ncdu", "-f-"], input=scanner.export())
sys.exit(res.returncode)
if __name__ == "__main__":
main()
How to right click
I climbed on top of a mountain with a beautiful view, and when I started readying my new laptop for a work call (as one does on top of mountains), I realised that I couldn't right click and it kind of spoiled the mood.
Clicking on the bottom right corner of my touchpad left-clicked. Clicking with two fingers left-clicked. Alt-clicking, Super-clicking, Control-clicking, left clicked.
Here's there are two ways to simulate mouse buttons with touchpads in Wayland:
- clicking on different areas at the bottom of the touchpad
- double or triple-tapping, as long as the fingers are not too far apart
Skippable digression:
I'm not sure why Gnome insists in following Macs for defaults, which is what people with non-Mac hardware are less likely to be used to.
In my experience, Macs are as arbitrarily awkward to use as anything else, but they managed to build a community where if you don't understand how it works you get told you're stupid. All other systems (including Gnome) have communities where instead you get told (as is generally the case) that the system design is stupid, which at least gives you some amount of validation in your suffering.
Oh well.
How to configure right click
Surprisingly, this is not available in Gnome Shell settings. It can be found in gnome-tweaks: under "Keyboard & Mouse", "Mouse Click Emulation", one can choose between "Fingers" or "Area".
I tried both and went for "Area": I use right-drag a lot to resize windows, and I couldn't find a way, at least with this touchpad, to make it work consistently in "Fingers" mode.
New laptop setup
My new laptop Framework (Framework Laptop 13 DIY Edition (AMD Ryzen™ 7040 Series)) arrived, all the hardware works out of the box on Debian Stable, and I'm very happy indeed.
This post has the notes of all the provisioning steps, so that I can replicate them again if needed.
Installing Debian 12
Debian 12's installer just worked, with Secure Boot enabled no less, which was nice.
The only glitch is an argument with the guided partitioner, which was uncooperative: I have been hit before by a /boot partition too small, and I wanted 1G of EFI and 1G of boot, while the partitioner decided that 512Mb were good enough. Frustratingly, there was no way of changing that, nor I found how to get more than 1G of swap, as I wanted enough swap to fit RAM for hybernation.
I let it install the way it pleased, then I booted into grml for a round of gparted.
The tricky part of that was resizing the root btrfs filesystem, which is in an LV, which is in a VG, which is in a PV, which is in LUKS. Here's a cheatsheet.
Shrink partitions:
- mount the root filesystem in
/mnt - btrfs filesystem resize 6G
/mnt - umount the root filesystem
- lvresize -L 7G vgname/lvname
- pvresize --setphysicalvolumesize /dev/mapper/pvname 8G
- cryptsetup resize --device-size 9G name
note that I used an increasing size because I don't trust that each tool has a way of representing sizes that aligns to the byte. I'd be happy to find out that they do, but didn't want to find out the hard way that they didn't.
Resize with gparted:
Move and resize partitions at will. Shrinking first means it all takes a reasonable time, and you won't have to wait almost an hour for a terabyte-sized empty partition to be carefully moved around. Don't ask me why I know.
Regrow partitions:
- cryptsetup resize name
- pvresize /dev/mapper/pvname
- lvresize -L 100% vgname/lvname
- mount the root filesystem in
/mnt - btrfs filesystem resize max
/mnt - umount the root filesystem
Setup gnome
When I get a new laptop I have a tradition of trying to make it work with Gnome and Wayland, which normally ended up in frustration and a swift move to X11 and Xfce: I have a lot of long-time muscle memory involved in how I use a computer, and it needs to fit like prosthetics. I can learn to do a thing or two in a different way, but any papercut that makes me break flow and I cannot fix will soon become a dealbreaker.
This applies to Gnome as present in Debian Stable.
General Gnome settings tips
I can list all available settings with:
gsettings list-recursively
which is handy for grepping things like hotkeys.
I can manually set a value with:
gsettings set <schema> <key> <value>
and I can reset it to its default with:
gsettings reset <schema> <key>
Some applications like Gnome Terminal use "relocatable schemas", and in those cases you also need to specify a path, which can be discovered using dconf-editor:
gsettings set <schema>:<path> <key> <value>
Install appindicators
First thing first: app install gnome-shell-extension-appindicator, log out
and in again: the Gnome Extension manager won't see the extension as available
until you restart the whole session.
I have no idea why that is so, and I have no idea why a notification area is not present in Gnome by default, but at least now I can get one.
Fix font sizes across monitors
My laptop screen and monitor have significantly different DPIs, so:
gsettings set org.gnome.mutter experimental-features "['scale-monitor-framebuffer']"
And in Settings/Displays, set a reasonable scaling factor for each display.
Disable Alt/Super as hotkey for the Overlay
Seeing all my screen reorganize and reshuffle every time I accidentally press Alt leaves me disoriented and seasick:
gsettings set org.gnome.mutter overlay-key ''
Focus-follows-mouse and Raise-or-lower
My desktop is like my desktop: messy and cluttered. I have lots of overlapping window and I switch between them by moving the focus with the mouse, and when the visible part is not enough I have a handy hotkey mapped to raise-or-lower to bring forward what I need and send back what I don't need anymore.
Thankfully Gnome can be configured that way, with some work:
- In gnome-shell settings, keyboard, shortcuts, windows, set "Raise window if covered, otherwise lower it" to "Super+Escape"
- In gnome-tweak-tool, Windows, set "Focus on Hover"
This almost worked, but sometimes it didn't do what I wanted, like I expected to find a window to the front but another window disappeared instead. I eventually figured that by default Gnome delays focus changes by a perceivable amount, which is evidently too slow for the way I move around windows.
The amount cannot be shortened, but it can be removed with:
gsettings set org.gnome.shell.overrides focus-change-on-pointer-rest false
Mouse and keyboard shortcuts
Gnome has lots of preconfigured sounds, shortcuts, animations and other distractions that I do not need. They also either interfere with key combinations I want to use in terminals, or cause accidental window moves or resizes that make me break flow, or otherwise provide sensory overstimulation that really does not work for me.
It was a lot of work, and these are the steps I used to get rid of most of them.
Disable Super+N combinations that accidentally launch a questionable choice of programs:
for i in `seq 1 9`; do gsettings set org.gnome.shell.keybindings switch-to-application-$i '[]'; done
Gnome-Shell settings:
- Multitasking:
- disable hot corner
- disable active edges
- set a fixed number of workspaces
- workspaces on all displays
- switching includes apps from current workspace only
- Sound:
- disable system sounds
- Keyboard
- Compose Key set to Caps Lock
- View and Customize Shortcuts:
- Launchers
- launch help browser: remove
- Navigation
- move to workspace on the left: Super+Left
- move to workspace on the right: Super+Right
- move window one monitor …: remove
- move window one workspace to the left: Shift+Super+Left
- move window one workspace to the right: Shift+Super+Right
- move window to …: remove
- switch system …: remove
- switch to …: remove
- switch windows …: disabled
- Screenshots
- Record a screenshot interactively: Super+Print
- Take a screenshot interactively: Print
- Disable everything else
- System
- Focus the active notification: remove
- Open the applcation menu: remove
- Restore the keyboard shortctus: remove
- Show all applications: remove
- Show the notification list: remove
- Show the overvire: remove
- Show the run command prompt: remove (the default Gnome launcher is not for me) Super+F2 (or remove to leave it to the terminal)
- Windows
- Close window: remove
- Hide window: remove
- Maximize window: remove
- Move window: remove
- Raise window if covered, otherwise lower it: Super+Escape
- Resize window: remove
- Restore window: remove
- Toggle maximization state: remove
- Launchers
- Custom shortcuts
- xfrun4, launching xfrun4, bound to Super+F2
- Accessibility:
- disable "Enable animations"
gnome-tweak-tool settings:
- Keyboard & Mouse
- Overview shortcut: Right Super. This cannot be disabled, but since my keyboard doesn't have a Right Super button, that's good enough for me. Oddly, I cannot find this in gsettings.
- Window titlebars
- Double-Click: Toggle-Maximize
- Middle-Click: Lower
- Secondary-Click: Menu
- Windows
- Resize with secondary click
Gnome Terminal settings:
Thankfully 10 years ago I took notes on how to customize Gnome Terminal, and they're still mostly valid:
-
Shortcuts
- New tab: Super+T
- New window: Super+N
- Close tab: disabled
- Close window: disabled
- Copy: Super+C
- Paste: Super+V
- Search: all disabled
- Previous tab: Super+Page Up
- Next tab: Super+Page Down
- Move tab…: Disabled
- Switch to tab N: Super+Fn (only available after disabling overview)
-
Switch to tab N with Alt+Fn cannot be configured in the UI:
Alt+Fnis detected as simplyFn. It can however be set with gsettings:sh for i in `seq 1 12`; do gsettings set org.gnome.Terminal.Legacy.Keybindings:/org/gnome/terminal/legacy/keybindings/ switch-to-tab-$i "<Alt>F$i"; done
-
Profile
- Text
- Sound: disable terminal bell
- Text
Other hotkeys that got in my way and had to disable the hard way:
for n in `seq 1 12`; do gsettings set org.gnome.mutter.wayland.keybindings switch-to-session-$n '[]'; done
gsettings set org.gnome.desktop.wm.keybindings move-to-workspace-down '[]'
gsettings set org.gnome.desktop.wm.keybindings move-to-workspace-up '[]'
gsettings set org.gnome.desktop.wm.keybindings panel-main-menu '[]'
gsettings set org.gnome.desktop.interface menubar-accel '[]'
Note that even after removing F10 from being bound to menubar-accel, and after having to gsetting binding to F10 as is:
$ gsettings list-recursively|grep F10
org.gnome.Terminal.Legacy.Keybindings switch-to-tab-10 '<Alt>F10'
I still cannot quit Midnight Commander using F10 in a terminal, as that moves the focus in the window title bar. This looks like a Gnome bug, and a very frustrating one for me.
Appearance
Gnome-Shell settings:
- Appearance:
- dark mode
gnome-tweak-tool settings:
- Fonts
- Antialiasing: Subpixel
- Top Bar
- Clock/Weekday: enable (why is this not a default?)
Gnome Terminal settings:
- General
- Theme variant: Dark (somehow it wasn't picked by up from the system settings)
- Profile
- Colors
- Background: #000
- Colors
Other decluttering and tweaks
Gnome Shell Settings:
- Search
- disable application search
- Removable media
- set everything to "ask what to do"
- Default applications
- Web: Chromium
- Mail: mutt
- Calendar: khal is not sadly an option
- Video: mpv
- Photos: Geequie
Set a delay between screen blank and lock: when the screen goes blank, it is important for me to be able to say "nope, don't blank yet!", and maybe switch on caffeine mode during a presentation without needing to type my password in front of cameras. No UI for this, but at least gsettings has it:
gsettings set org.gnome.desktop.screensaver lock-delay 30
Extensions
I enabled the Applications Menu extension, since it's impossible to find less famous applications in the Overview without knowing in advance how they're named in the desktop. This stole a precious hotkey, which I had to disable in gsettings:
gsettings set org.gnome.shell.extensions.apps-menu apps-menu-toggle-menu '[]'
I also enabled:
- Removable Drive Menu: why is this not on by default?
- Workspace Indicator
- Ubuntu Appindicators (apt install gnome-shell-extension-appindicator and restart Gnome)
I didn't go and look for Gnome Shell extentions outside what is packaged in Debian, as I'm very wary about running JavaScript code randomly downloaded from the internet with full access over my data and desktop interaction.
I also took care of checking that the Gnome Shell Extensions web page complains about the lacking "GNOME Shell integration" browser extension, because the web browser shouldn't be allowed to download random JavaScript from the internet and run it with full local access.
Yuck.
Run program dialog
The default run program dialog is almost, but not quite, totally useless to me, as it does not provide completion, not even just for executable names in path, and so it ends up being faster to open a new terminal window and type in there.
It's possible, in Gnome Shell settings, to bind a custom command to a key. The resulting keybinding will now show up in gsettings, though it can be located in a more circuitous way by grepping first, and then looking up the resulting path in dconf-editor:
gsettings list-recursively|grep custom-key
org.gnome.settings-daemon.plugins.media-keys custom-keybindings ['/org/gnome/settings-daemon/plugins/media-keys/custom-keybindings/custom0/']
I tried out several run dialogs present in Debian, with sad results, possibly due to most of them not being tested on wayland:
- fuzzel does not start
- gmrun is gtk2, last updated in 2016, but works fine
- kupfer segfaults as I type
- rofi shows, but can't get keboard input
- shellex shows a white bar at top of the screen and lots of errors on stderr
- superkb wants to grab the screen for hotkeys
- synapse searched news on the internet as I typed, which is a big no for me
- trabucco crashes on startup
- wofi works but looks like very much an acquired taste, though it has some completion that makes it more useful than Gnome's run dialog
- xfrun4 (package xfce4-appfinder) struggles on wayland, being unable to center its window and with the pulldown appearing elsewhere in the screen, but it otherwise works
Both gmrun and xfrun4 seem like workable options, with xfrun4 being customizable with convenient shortcut prefixes, so xfrun4 it is.
TODO
- Figure out what is still binding F10 to menu, and what I can do about it
- Figure out how to reduce the size of window titlebars, which to my taste should be unobtrusive and not take 2.7% of vertical screen size each. There's a minwaita theme which isn't packaged in Debian. There's a User Theme extension, and then the whole theming can of worms to open. For another day.
- Figure out if Gnome can be convinced to resize popup windows? Take the Gnome Terminal shortcut preferences for example: it takes ⅓ of the vertical screen and can only display ¼ of all available shortcuts, and I cannot find a valid reason why I shouldn't be allowed to enlarge it vertically.
- Figure out if I can place shortcut launcher icons in the top panel, and how
I'll try to update these notes as I investigate.
Conclusion so far
I now have something that seems to work for me. A few papercuts to figure out still, but they seem manageable.
It all feels a lot harder than it should be: for something intended to be minimal, Gnome defaults feel horribly cluttered and noisy to me, continuosly getting in the way of getting things done until tamed into being out of the way unless called for. It felt like a device that boots into flashy demo mode, which needs to be switched off before actual use.
Thankfully it can be switched off, and now I have notes to do it again if needed.
gsettings oddly feels to me like a better UI than the interactive settings
managers: it's more comprehensive, more discoverable, more scriptable, and more
stable across releases. Most of the Q&A I found on the internet with guidance
given on the UI was obsolete, while when given with gsettings command lines
it kept being relevant. I also have the feeling that these notes would be
easier to understand and follow if given as gsettings invocations instead of
descriptions of UI navigation paths.
At some point I'll upgrade to Trixie and reevaluate things, and these notes will be a useful checklist for that.
Fingers crossed that this time I'll manage to stay on Wayland. If not, I know that Xfce is still there for me, and I can trust it to be both helpful and good at not getting in the way of my work.
meson, includedir, and current directory
Suppose you have a meson project like this:
meson.build:
project('example', 'cpp', version: '1.0', license : '…', default_options: ['warning_level=everything', 'cpp_std=c++17'])
subdir('example')
example/meson.build:
test_example = executable('example-test', ['main.cc'])
example/string.h:
/* This file intentionally left empty */
example/main.cc:
#include <cstring>
int main(int argc,const char* argv[])
{
std::string foo("foo");
return 0;
}
This builds fine with autotools and cmake, but not meson:
$ meson setup builddir
The Meson build system
Version: 1.0.1
Source dir: /home/enrico/dev/deb/wobble-repr
Build dir: /home/enrico/dev/deb/wobble-repr/builddir
Build type: native build
Project name: example
Project version: 1.0
C++ compiler for the host machine: ccache c++ (gcc 12.2.0 "c++ (Debian 12.2.0-14) 12.2.0")
C++ linker for the host machine: c++ ld.bfd 2.40
Host machine cpu family: x86_64
Host machine cpu: x86_64
Build targets in project: 1
Found ninja-1.11.1 at /usr/bin/ninja
$ ninja -C builddir
ninja: Entering directory `builddir'
[1/2] Compiling C++ object example/example-test.p/main.cc.o
FAILED: example/example-test.p/main.cc.o
ccache c++ -Iexample/example-test.p -Iexample -I../example -fdiagnostics-color=always -D_FILE_OFFSET_BITS=64 -Wall -Winvalid-pch -Wextra -Wpedantic -Wcast-qual -Wconversion -Wfloat-equal -Wformat=2 -Winline -Wmissing-declarations -Wredundant-decls -Wshadow -Wundef -Wuninitialized -Wwrite-strings -Wdisabled-optimization -Wpacked -Wpadded -Wmultichar -Wswitch-default -Wswitch-enum -Wunused-macros -Wmissing-include-dirs -Wunsafe-loop-optimizations -Wstack-protector -Wstrict-overflow=5 -Warray-bounds=2 -Wlogical-op -Wstrict-aliasing=3 -Wvla -Wdouble-promotion -Wsuggest-attribute=const -Wsuggest-attribute=noreturn -Wsuggest-attribute=pure -Wtrampolines -Wvector-operation-performance -Wsuggest-attribute=format -Wdate-time -Wformat-signedness -Wnormalized=nfc -Wduplicated-cond -Wnull-dereference -Wshift-negative-value -Wshift-overflow=2 -Wunused-const-variable=2 -Walloca -Walloc-zero -Wformat-overflow=2 -Wformat-truncation=2 -Wstringop-overflow=3 -Wduplicated-branches -Wattribute-alias=2 -Wcast-align=strict -Wsuggest-attribute=cold -Wsuggest-attribute=malloc -Wanalyzer-too-complex -Warith-conversion -Wbidi-chars=ucn -Wopenacc-parallelism -Wtrivial-auto-var-init -Wctor-dtor-privacy -Weffc++ -Wnon-virtual-dtor -Wold-style-cast -Woverloaded-virtual -Wsign-promo -Wstrict-null-sentinel -Wnoexcept -Wzero-as-null-pointer-constant -Wabi-tag -Wuseless-cast -Wconditionally-supported -Wsuggest-final-methods -Wsuggest-final-types -Wsuggest-override -Wmultiple-inheritance -Wplacement-new=2 -Wvirtual-inheritance -Waligned-new=all -Wnoexcept-type -Wregister -Wcatch-value=3 -Wextra-semi -Wdeprecated-copy-dtor -Wredundant-move -Wcomma-subscript -Wmismatched-tags -Wredundant-tags -Wvolatile -Wdeprecated-enum-enum-conversion -Wdeprecated-enum-float-conversion -Winvalid-imported-macros -std=c++17 -O0 -g -MD -MQ example/example-test.p/main.cc.o -MF example/example-test.p/main.cc.o.d -o example/example-test.p/main.cc.o -c ../example/main.cc
In file included from ../example/main.cc:1:
/usr/include/c++/12/cstring:77:11: error: ‘memchr’ has not been declared in ‘::’
77 | using ::memchr;
| ^~~~~~
/usr/include/c++/12/cstring:78:11: error: ‘memcmp’ has not been declared in ‘::’
78 | using ::memcmp;
| ^~~~~~
/usr/include/c++/12/cstring:79:11: error: ‘memcpy’ has not been declared in ‘::’
79 | using ::memcpy;
| ^~~~~~
/usr/include/c++/12/cstring:80:11: error: ‘memmove’ has not been declared in ‘::’
80 | using ::memmove;
| ^~~~~~~
…
It turns out that meson adds the current directory to the include path by default:
Another thing to note is that
include_directoriesadds both the source directory and corresponding build directory to include path, so you don't have to care.
It seems that I have to care after all.
Thankfully there is an implicit_include_directories setting
that can turn this off if needed.
Its documentation is not as easy to find as I'd like (kudos to Kangie on IRC), and hopefully this blog post will make it easier for me to find it in the future.
Introducing Debusine
Abstract
Debusine manages scheduling and distribution of Debian-related tasks (package build, lintian analysis, autopkgtest runs, etc.) to distributed worker machines. It is being developed by Freexian with the intention of giving people access to a range of pre-configured tools and workflows running on remote hardware.
Freexian obtained STF funding for a substantial set of Debusine milestones, so development is happening on a clear schedule. We can present where we are and, we're going to be, and what we hope to bring to Debian with this work.
Adulting
Abstract
Although Debian has just turned 30, in my experience it has not yet fully turned adult: we sometimes squabble like boys in puberty, like children we assume that someone takes care of paying the bills and bringing out the trash, we procrastinate on our responsibilities and hope nobody notices.
At the same time, we cannot assume that people have the energy and motivation to do what is needed to keep the house clean and the boat afloat: Debian is based on people volunteering, and people have diverse and changing reasons to be with us, and private lives, loved ones and families, bills to be paid.
I want to start figuring out how to address practical issues around the sustainability of the Debian community, in a way that fits the needs and peculiarities of the Debian community.
The end does not justify the means: really, the means define what the end will be. I want to talk about the means: how to be sustainable, how to be interesting, how to be fun, how to have a community worth caring for, how to last for centuries
Regular virus scan
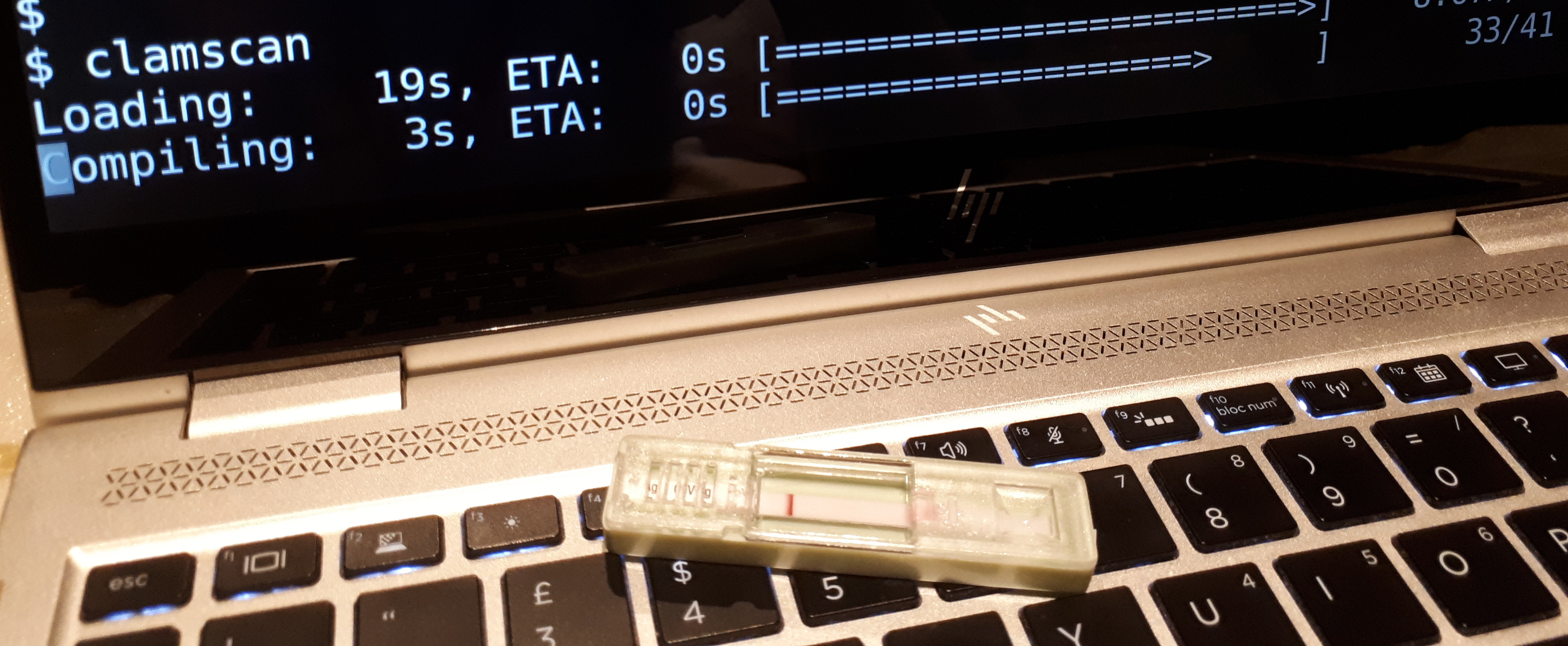
Debian: when you're more likely to get a virus than your laptop
Mysterious DNS issues

Uhm, salsa is not resolving:
$ git fetch
ssh: Could not resolve hostname salsa.debian.org: Name or service not known
fatal: Could not read from remote repository.
$ ping salsa.debian.org
ping: salsa.debian.org: Name or service not known
But... it is?
$ host salsa.debian.org
salsa.debian.org has address 209.87.16.44
salsa.debian.org has IPv6 address 2607:f8f0:614:1::1274:44
salsa.debian.org mail is handled by 10 mailly.debian.org.
salsa.debian.org mail is handled by 10 mitropoulos.debian.org.
salsa.debian.org mail is handled by 10 muffat.debian.org.
It really is resolving correctly at each step:
$ cat /etc/resolv.conf
# This is /run/systemd/resolve/stub-resolv.conf managed by man:systemd-resolved(8).
# Do not edit.
# [...]
# Run "resolvectl status" to see details about the uplink DNS servers
# currently in use.
# [...]
nameserver 127.0.0.53
options edns0 trust-ad
search fritz.box
$ host salsa.debian.org 127.0.0.53
Using domain server:
Name: 127.0.0.53
Address: 127.0.0.53#53
Aliases:
salsa.debian.org has address 209.87.16.44
salsa.debian.org has IPv6 address 2607:f8f0:614:1::1274:44
salsa.debian.org mail is handled by 10 mailly.debian.org.
salsa.debian.org mail is handled by 10 muffat.debian.org.
salsa.debian.org mail is handled by 10 mitropoulos.debian.org.
# resolvectl status
Global
Protocols: +LLMNR +mDNS -DNSOverTLS DNSSEC=no/unsupported
resolv.conf mode: stub
Link 3 (wlp108s0)
Current Scopes: DNS LLMNR/IPv4 LLMNR/IPv6
Protocols: +DefaultRoute +LLMNR -mDNS -DNSOverTLS DNSSEC=no/unsupported
Current DNS Server: 192.168.178.1
DNS Servers: 192.168.178.1 fd00::3e37:12ff:fe99:2301 2a01:b600:6fed:1:3e37:12ff:fe99:2301
DNS Domain: fritz.box
Link 4 (virbr0)
Current Scopes: none
Protocols: -DefaultRoute +LLMNR -mDNS -DNSOverTLS DNSSEC=no/unsupported
Link 9 (enxace2d39ce693)
Current Scopes: DNS LLMNR/IPv4 LLMNR/IPv6
Protocols: +DefaultRoute +LLMNR -mDNS -DNSOverTLS DNSSEC=no/unsupported
Current DNS Server: 192.168.178.1
DNS Servers: 192.168.178.1 fd00::3e37:12ff:fe99:2301 2a01:b600:6fed:1:3e37:12ff:fe99:2301
DNS Domain: fritz.box
$ host salsa.debian.org 192.168.178.1
Using domain server:
Name: 192.168.178.1
Address: 192.168.178.1#53
Aliases:
salsa.debian.org has address 209.87.16.44
salsa.debian.org has IPv6 address 2607:f8f0:614:1::1274:44
salsa.debian.org mail is handled by 10 muffat.debian.org.
salsa.debian.org mail is handled by 10 mitropoulos.debian.org.
salsa.debian.org mail is handled by 10 mailly.debian.org.
$ host salsa.debian.org fd00::3e37:12ff:fe99:2301 2a01:b600:6fed:1:3e37:12ff:fe99:2301
Using domain server:
Name: fd00::3e37:12ff:fe99:2301
Address: fd00::3e37:12ff:fe99:2301#53
Aliases:
salsa.debian.org has address 209.87.16.44
salsa.debian.org has IPv6 address 2607:f8f0:614:1::1274:44
salsa.debian.org mail is handled by 10 muffat.debian.org.
salsa.debian.org mail is handled by 10 mitropoulos.debian.org.
salsa.debian.org mail is handled by 10 mailly.debian.org.
Could it be caching?
# systemctl restart systemd-resolved
$ dpkg -s nscd
dpkg-query: package 'nscd' is not installed and no information is available
$ git fetch
ssh: Could not resolve hostname salsa.debian.org: Name or service not known
fatal: Could not read from remote repository.
Could it be something in ssh's config?
$ grep salsa ~/.ssh/config
$ ssh git@salsa.debian.org
ssh: Could not resolve hostname salsa.debian.org: Name or service not known
Something weird with ssh's control sockets?
$ strace -fo /tmp/zz ssh git@salsa.debian.org
ssh: Could not resolve hostname salsa.debian.org: Name or service not known
enrico@ploma:~/lavori/legal/legal$ grep salsa /tmp/zz
393990 execve("/usr/bin/ssh", ["ssh", "git@salsa.debian.org"], 0x7ffffcfe42d8 /* 54 vars */) = 0
393990 connect(3, {sa_family=AF_UNIX, sun_path="/home/enrico/.ssh/sock/git@salsa.debian.org:22"}, 110) = -1 ENOENT (No such file or directory)
$ strace -fo /tmp/zz1 ssh -S none git@salsa.debian.org
ssh: Could not resolve hostname salsa.debian.org: Name or service not known
$ grep salsa /tmp/zz1
394069 execve("/usr/bin/ssh", ["ssh", "-S", "none", "git@salsa.debian.org"], 0x7ffd36cbfde8 /* 54 vars */) = 0
How is ssh trying to resolve salsa.debian.org?
393990 socket(AF_UNIX, SOCK_STREAM|SOCK_CLOEXEC|SOCK_NONBLOCK, 0) = 3
393990 connect(3, {sa_family=AF_UNIX, sun_path="/run/systemd/resolve/io.systemd.Resolve"}, 42) = 0
393990 sendto(3, "{\"method\":\"io.systemd.Resolve.Re"..., 99, MSG_DONTWAIT|MSG_NOSIGNAL, NULL, 0) = 99
393990 mmap(NULL, 135168, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f4fc71ca000
393990 recvfrom(3, 0x7f4fc71ca010, 135152, MSG_DONTWAIT, NULL, NULL) = -1 EAGAIN (Resource temporarily unavailable)
393990 ppoll([{fd=3, events=POLLIN}], 1, {tv_sec=119, tv_nsec=999917000}, NULL, 8) = 1 ([{fd=3, revents=POLLIN}], left {tv_sec=119, tv_nsec=998915689})
393990 recvfrom(3, "{\"error\":\"io.systemd.System\",\"pa"..., 135152, MSG_DONTWAIT, NULL, NULL) = 56
393990 rt_sigprocmask(SIG_SETMASK, [], NULL, 8) = 0
393990 close(3) = 0
393990 munmap(0x7f4fc71ca000, 135168) = 0
393990 getpid() = 393990
393990 write(2, "ssh: Could not resolve hostname "..., 77) = 77
Something weird with resolved?
$ resolvectl query salsa.debian.org
salsa.debian.org: resolve call failed: Lookup failed due to system error: Invalid argument
Let's try disrupting what ssh is trying and failing:
# mv /run/systemd/resolve/io.systemd.Resolve /run/systemd/resolve/io.systemd.Resolve.backup
$ strace -o /tmp/zz2 ssh -S none -vv git@salsa.debian.org
OpenSSH_9.2p1 Debian-2, OpenSSL 3.0.9 30 May 2023
debug1: Reading configuration data /home/enrico/.ssh/config
debug1: /home/enrico/.ssh/config line 1: Applying options for *
debug1: /home/enrico/.ssh/config line 228: Applying options for *.debian.org
debug1: Reading configuration data /etc/ssh/ssh_config
debug1: /etc/ssh/ssh_config line 19: include /etc/ssh/ssh_config.d/*.conf matched no files
debug1: /etc/ssh/ssh_config line 21: Applying options for *
debug2: resolving "salsa.debian.org" port 22
ssh: Could not resolve hostname salsa.debian.org: Name or service not known
$ tail /tmp/zz2
394748 prctl(PR_CAPBSET_READ, 0x29 /* CAP_??? */) = -1 EINVAL (Invalid argument)
394748 munmap(0x7f27af5ef000, 164622) = 0
394748 rt_sigprocmask(SIG_BLOCK, [HUP USR1 USR2 PIPE ALRM CHLD TSTP URG VTALRM PROF WINCH IO], [], 8) = 0
394748 futex(0x7f27ae5feaec, FUTEX_WAKE_PRIVATE, 2147483647) = 0
394748 openat(AT_FDCWD, "/run/systemd/machines/salsa.debian.org", O_RDONLY|O_CLOEXEC) = -1 ENOENT (No such file or directory)
394748 rt_sigprocmask(SIG_SETMASK, [], NULL, 8) = 0
394748 getpid() = 394748
394748 write(2, "ssh: Could not resolve hostname "..., 77) = 77
394748 exit_group(255) = ?
394748 +++ exited with 255 +++
$ machinectl list
No machines.
# resolvectl flush-caches
$ resolvectl query salsa.debian.org
salsa.debian.org: resolve call failed: Lookup failed due to system error: Invalid argument
# resolvectl reset-statistics
$ resolvectl query salsa.debian.org
salsa.debian.org: resolve call failed: Lookup failed due to system error: Invalid argument
# resolvectl reset-server-features
$ resolvectl query salsa.debian.org
salsa.debian.org: resolve call failed: Lookup failed due to system error: Invalid argument
# resolvectl monitor
→ Q: salsa.debian.org IN A
→ Q: salsa.debian.org IN AAAA
← S: EINVAL
← A: debian.org IN NS sec2.rcode0.net
← A: debian.org IN NS sec1.rcode0.net
← A: debian.org IN NS nsp.dnsnode.net
← A: salsa.debian.org IN A 209.87.16.44
← A: debian.org IN NS dns4.easydns.info
I guess I won't be using salsa today, and I wish I understood why.
Update: as soon as I pushed this post to my blog (via ssh) salsa started resolving again.
Handling keyboard-like devices

I acquired some unusual input devices to experiment with, like a CNC control panel and a bluetooth pedal page turner.
These identify and behave like a keyboard, sending nice and simple keystrokes, and can be accessed with no drivers or other special software. However, their keystrokes appear together with keystrokes from normal keyboards, which is the expected default when plugging in a keyboard, but not what I want in this case.
I'd also like them to be readable via evdev and accessible by my own user.
Here's the udev rule I cooked up to handle this use case:
# Handle the CNC control panel
SUBSYSTEM=="input", ENV{ID_VENDOR}=="04d9", ENV{ID_MODEL}=="1203", \
OWNER="enrico", ENV{ID_INPUT}=""
# Handle the Bluetooth page turner
SUBSYSTEM=="input", ENV{ID_BUS}=="bluetooth", ENV{LIBINPUT_DEVICE_GROUP}=="*/…mac…", ENV{ID_INPUT_KEYBOARD}="1" \
OWNER="enrico", ENV{ID_INPUT}="", SYMLINK+="input/by-id/bluetooth-…mac…-kbd"
SUBSYSTEM=="input", ENV{ID_BUS}=="bluetooth", ENV{LIBINPUT_DEVICE_GROUP}=="*/…mac…", ENV{ID_INPUT_TABLET}="1" \
OWNER="enrico", ENV{ID_INPUT}="", SYMLINK+="input/by-id/bluetooth-…mac…-tablet"
The bluetooth device didn't have standard rules to create /dev/input/by-id/
symlinks so I added them. In my own code, I watch /dev/input/by-id with
inotify to handle when devices appear or disappear.
I used udevadm info /dev/input/event… to see what I could use to identify the
device.
The Static device configuration via udev page of libinput's documentation has documentation on the various elements specific to the input subsystem
Grepping rule files in /usr/lib/udev/rules.d was useful to see syntax
examples.
udevadm test /dev/input/event… was invaluable for syntax checking and testing
my rule file while working on it.
Finally, this is an extract of a quick prototype Python code to read keys from the CNC control panel:
import libevdev
KEY_MAP = {
libevdev.EV_KEY.KEY_GRAVE: "EMERGENCY",
# InputEvent(EV_KEY, KEY_LEFTALT, 1)
libevdev.EV_KEY.KEY_R: "CYCLE START",
libevdev.EV_KEY.KEY_F5: "SPINDLE ON/OFF",
# InputEvent(EV_KEY, KEY_RIGHTCTRL, 1)
libevdev.EV_KEY.KEY_W: "REDO",
# InputEvent(EV_KEY, KEY_LEFTALT, 1)
libevdev.EV_KEY.KEY_N: "SINGLE STEP",
# InputEvent(EV_KEY, KEY_LEFTCTRL, 1)
libevdev.EV_KEY.KEY_O: "ORIGIN POINT",
libevdev.EV_KEY.KEY_ESC: "STOP",
libevdev.EV_KEY.KEY_KPPLUS: "SPEED UP",
libevdev.EV_KEY.KEY_KPMINUS: "SLOW DOWN",
libevdev.EV_KEY.KEY_F11: "F+",
libevdev.EV_KEY.KEY_F10: "F-",
libevdev.EV_KEY.KEY_RIGHTBRACE: "J+",
libevdev.EV_KEY.KEY_LEFTBRACE: "J-",
libevdev.EV_KEY.KEY_UP: "+Y",
libevdev.EV_KEY.KEY_DOWN: "-Y",
libevdev.EV_KEY.KEY_LEFT: "-X",
libevdev.EV_KEY.KEY_RIGHT: "+X",
libevdev.EV_KEY.KEY_KP7: "+A",
libevdev.EV_KEY.KEY_Q: "-A",
libevdev.EV_KEY.KEY_PAGEDOWN: "-Z",
libevdev.EV_KEY.KEY_PAGEUP: "+Z",
}
class KeyReader:
def __init__(self, path: str):
self.path = path
self.fd: IO[bytes] | None = None
self.device: libevdev.Device | None = None
def __enter__(self):
self.fd = open(self.path, "rb")
self.device = libevdev.Device(self.fd)
return self
def __exit__(self, exc_type, exc, tb):
self.device = None
self.fd.close()
self.fd = None
def events(self) -> Iterator[dict[str, Any]]:
for e in self.device.events():
if e.type == libevdev.EV_KEY:
if (val := KEY_MAP.get(e.code)):
yield {
"name": val,
"value": e.value,
"sec": e.sec,
"usec": e.usec,
}
Edited: added rules to handle the Bluetooth page turner